2024년 6월 4일, 엔비디아의 CEO 젠슨 황은 2026년에 출시 예정인 차세대 AI 칩 플랫폼 ‘루빈(Rubin)’을 발표했습니다. 이번 발표는 AI 하드웨어 기술의 중요한 전환점을 예고하며, 엔비디아가 AI 칩 시장에서의 리더십을 더욱 공고히 다지기 위한 전략적 로드맵을 제시했습니다. 이번 포스팅에서는 루빈 AI 플랫폼의 주요 특징과 기술적 혁신, 그리고 AI 성능 향상에 미치는 영향을 심층적으로 살펴보겠습니다.
루빈 AI 플랫폼의 주요 특징
- 고성능 하드웨어 구성
- GPU와 CPU: 루빈 제품군에는 차세대 그래픽 프로세싱 유닛(GPU)과 중앙 프로세싱 유닛(CPU)이 포함됩니다. 특히, 새로운 Arm 기반 CPU인 ‘베라(Vera)’가 탑재되어 고성능과 효율성을 제공합니다.
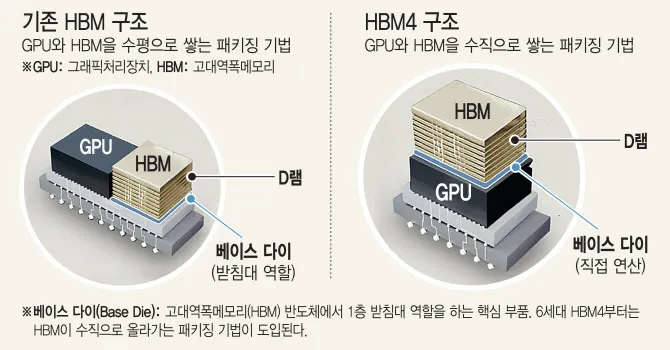
- HBM4 메모리: 6세대 고대역폭 메모리(HBM4)가 탑재될 예정으로, AI 작업 성능을 크게 향상시킬 것으로 기대됩니다.
- TSMC 3nm 공정: 고효율 저전력 반도체 기술이 적용될 전망입니다.
- CoWoS-L 패키징 기술: GPU와 메모리 간 고속 인터커넥트를 지원하여 데이터 전송 속도를 극대화합니다.
- 명확한 로드맵
- 2025년: ‘블랙웰 울트라(Blackwell Ultra)’ 출시 예정.
- 2026년: 루빈 제품군 양산.
- 2027년: 루빈 울트라(개량형) 양산 예정.
- 연간 신제품 출시: 매년 새로운 AI 칩 플랫폼을 출시하여 기술적 혁신을 지속할 계획입니다.
- 기대효과
- 엔비디아의 AI 칩 시장 주도권 강화.
- 삼성전자, SK하이닉스 등 HBM 기업들의 HBM4 로드맵 가속화.
- 엔비디아 주가 상승 및 10조 달러 기업가치 전망.
HBM4 기술의 장점 및 AI 성능 향상
- 데이터 처리 속도 향상
- 높은 대역폭: HBM4는 HBM3 대비 데이터 전송 속도가 2배 이상 높아 초당 2TB의 대역폭을 제공합니다. 이를 통해 대규모 AI 모델과 빅데이터 처리 성능이 크게 높아집니다.
- 낮은 지연시간: 하이브리드 본딩 기술을 적용하여 GPU-메모리 간 지연시간을 최소화합니다. 이로 인해 AI 모델의 데이터 접근 속도가 크게 향상됩니다.
- 고속 인터커넥트: CoWoS-L 패키징 기술로 GPU-HBM4 간 고속 데이터 전송이 가능해집니다.
- 대용량 메모리
- HBM4는 최대 64GB의 용량을 지원하며, 루빈 울트라는 총 576GB의 메모리를 탑재할 수 있습니다. 이는 대규모 AI 모델과 데이터셋을 GPU 메모리에 로딩하여 고품질 학습이 가능하도록 합니다.
- 전력 효율 개선
- HBM4는 HBM3 대비 전력 소모가 크게 줄어, AI 데이터센터의 전력 비용 절감 및 탄소 배출 감소에 기여합니다.
- AI 연산 성능 극대화
- GPU의 연산 성능을 최대한 활용할 수 있게 해주는 고속 인터커넥트 기술로 AI 작업 처리량과 성능을 극대화합니다.
HBM4 기술이 AI 분야에 미치는 혁신적 영향
- 대규모 AI 모델 처리 능력 향상: 높은 대역폭과 대용량 메모리로 대규모 AI 모델과 데이터셋을 더 빠르게 처리할 수 있습니다.
- AI 모델 및 데이터 로딩 능력 향상: 고용량 메모리 덕분에 더 큰 AI 모델과 데이터를 로딩하여 더 높은 성능과 정확도를 기대할 수 있습니다.
- 전력 효율 개선: 낮은 전력 소모로 더 많은 GPU를 데이터센터에 배치하여 대규모 클러스터 환경을 구축할 수 있습니다.
- AI 연산 성능 극대화: GPU의 연산 성능을 최대한 활용하여 AI 작업의 효율성과 처리 속도를 극대화합니다.
엔비디아의 루빈 AI 플랫폼은 최신 기술을 바탕으로 AI 성능을 획기적으로 향상시킬 것으로 기대됩니다. HBM4의 높은 대역폭, 대용량 메모리, 낮은 전력 소모 등은 AI 모델의 학습 및 추론 성능을 크게 개선하여 AI 시스템의 전반적인 효율성을 높일 것입니다. 엔비디아는 이러한 기술적 혁신을 통해 AI 칩 시장에서의 주도권을 지속적으로 유지하고자 합니다.